
The rules of ‘spot the difference’ puzzles are simple: given two pictures—one original and one that has been subtly altered—a player must identify all the differences between them. Detecting all the ‘anomalies’ in the altered picture comes intuitively to humans, and with recent advances in machine learning, even computers can perform this basic task with relative ease.
Beyond fun and games, anomaly detection can be applied to more complex problems. For instance, a company that tracks the log-in activity on its e-payment platform would know the typical behavior of its users, but it also wants to flag any suspicious actions that may be taking place. Because of the large and multi-dimensional nature of datasets on user activity, more sophisticated machine learning techniques, such as generative adversarial networks (GANs), are required to accurately spot anomalies.
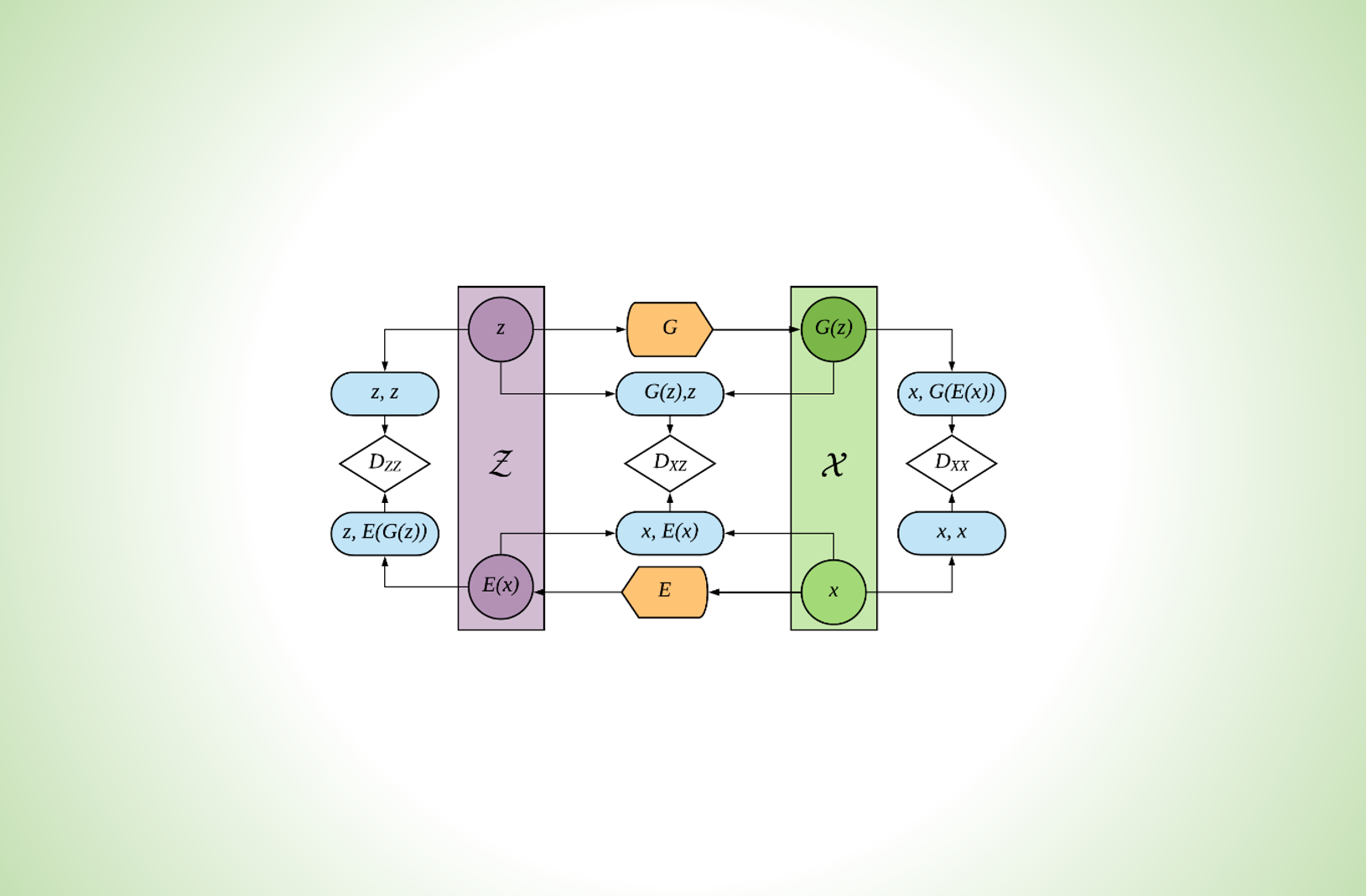
Essentially, GANs consist of two competing networks—a generator and a discriminator. The generator creates new data that mimics as closely as possible real-world data from random latent codes, while the discriminator seeks to distinguish between real-world data and those produced by the generator. The core idea behind GAN-based anomaly detection methods is that normal data (that the GAN is trained on) can be accurately reconstructed, while anomalous data cannot, much like how it is far easier for a human to sketch out a previously seen object than something completely new.
Reconstructing a particular data sample, however, requires a time-consuming optimization process to find its associated random latent code. “The only GAN-based anomaly detection method available at the time was extremely slow and impractical for use on large datasets,” said Chuan Sheng Foo of the Institute for Infocomm Research (I2R). “We wanted to develop a method that leveraged the power of GANs while still being fast.”
The researchers thus used a class of GANs that simultaneously learns an encoder network to, in effect, predict the associated random latent code for a data sample, thereby sidestepping the optimization routine to find the code. This allows for speedier anomaly detection.
“Once the GAN is trained, it can be used to detect anomalies by calculating a threshold value based on a novel anomaly score that quantifies the distance between the original samples and their reconstructions; higher scores reflect more anomalous examples,” Foo explained.
Applying this Adversarially Learned Anomaly Detection (ALAD) method to anomalies in image data as well as tabular data, the team demonstrated that their approach worked as well as, if not better than, other competing methods in terms of accuracy. ALAD was also much faster than the previous GAN-based techniques.
“We are exploring how ALAD and related techniques can be applied to time-series data such as sensor data from machines, for example. This could be useful for the predictive maintenance of machines,” Foo concluded.
The A*STAR-affiliated researchers contributing to this research are from the Institute for Infocomm Research (I2R).



